6. タリーセクションの共通書式¶
タリーセクションには、以下のセクションがあります。
name |
説明 |
|---|---|
[t-track] |
粒子の飛跡長 track length やフルエンスを導出するタリー。 |
[t-cross] |
粒子の面横断回数やフルエンスを導出するタリー。 |
[t-point] |
ある点や線上のフルエンスを導出するタリー。 |
[t-deposit] |
物質におけるエネルギー付与を導出するタリー。 |
[t-deposit2] |
2つの領域でのエネルギー付与の相関を出力するタリー。 |
[t-heat] |
物質におけるエネルギー付与を導出するタリー。(非推奨 [1] ) |
[t-yield] |
残留核の生成量を導出するタリー。 |
[t-product] |
線源や核反応による生成粒子を導出するタリー。 |
[t-dpa] |
原子あたりのはじき出し数 DPA を導出するタリー。 |
[t-let] |
LET の関数として飛跡長や線量を導出するタリー。 |
[t-sed] |
微小領域におけるエネルギー付与分布を導出するタリー。 |
[t-time] |
Time dependent tally。 |
[t-interact] (従来の [t-star] ) |
反応数を導出するタリー。 |
[t-dchain] |
DCHAIN 用入力ファイルを作成するタリー。 |
[t-wwg] |
[weight window] のパラメータを出力するタリー。 |
[t-wwbg] |
[ww bias] のパラメータを出力するタリー。 |
[t-volume] |
体積自動計算機能のためのタリー。 |
[t-userdefined] |
ユーザー定義による任意の物理量を導出するタリー。 |
[t-gshow] |
ジオメトリ(仮想空間)を2次元で表示するタリー。 |
[t-rshow] |
ジオメトリを2次元で物理量による色分けをして表示するタリー。 |
[t-3dshow] |
ジオメトリを3次元で表示するタリー。 |
[T-4Dtrack] |
PHIG-3Dで粒子の飛跡を表示するためのタリー。 |
本節では、これらのタリーセクションで共通に使われるパラメータの定義の仕方を説明します。
6.1. メッシュ型¶
上に示した各タリーでは、データを収集する幾何形状の種類として、領域メッシュ( reg )、r-z メッシュ( r-z )、xyz メッシュ( xyz )が使えます。 また、 [t-track] 、 [t-deposit] 、 [t-yield] 、 [t-product] 、 [t-dpa] 、 [t-dchain] でのみ使用可能な四面体メッシュ( tet )があります。
タリーセクションにおいてはこれらのメッシュを1つ指定する必要があり、次のような形式で指定します。
mesh = reg
6.1.1. 領域メッシュ¶
領域メッシュの場合、 mesh=reg とした次の実質行に reg= としてタリーするセル番号を指定します。 ここでいう実質行とは、コメント行や空行を除いた入力行を意味します。 mesh=reg と reg= の間に他のタリーパラメータを記述することはできません。
mesh = reg
reg = 1 2 { 3 - 5 } all
複数のセル番号は空白区切りで指定します。 また、 { n1 - n2 } の表式により、 n1 から n2 までのセル番号を一度に指定することができます。 上の例ではセル番号3から5のそれぞれを指定しており、 3 4 5 とした場合と同じ意味になります。 他に、 all とすることで定義した全てのセル番号を個別に指定できます。
幾つかのセル番号をまとめたい時は ( ) を用います。
mesh = reg
reg = ( 1 2 ) ( { 3 - 5 } ) ( all )
( 1 2 ) により、セル番号1と2の結果を合わせた値を出力します。 また、 ( { 3 - 5 } ) により、セル番号3、4、5の結果を一つに合計した値を出力します。 ただし、 ( n1 - n2 ) の表記は使用できないのでご注意ください。 他に、 (all) とすると、全てのセル番号の結果を合計した値を出力します。 これらの複数のセル番号をまとめた領域には、1000001より始まる識別番号が PHITS 内部で割り当てられます。 この識別番号はタリーの出力ファイルの最初の部分にエコーとして書き出され、次節で説明する volume サブセクションで適切な体積を与える際に使用されます。
Universe や lattice の機能を使用して計算体系(ジオメトリ)を定義した場合は、複数の空間(universe)を入れ子にした階層構造となります。 階層は < で表し、次のような形式でタリーする領域を指定します。
mesh = reg
reg = ( 301 < 101[0 0 0] )
階層構造を含む領域を指定する際は、必ず ( ) で囲まなくてはなりません。 この例は [cell] セクションにある リスト 5.6.9 の体系を参照しており、セル番号101の lattice 座標 \((0,0,0)\) に含まれているセル番号301の領域、という意味を表しています。 セル番号101の後ろにある [ ] によりタリーの対象とする lattice 座標を指定します。 Lattice 座標については 5.6.3 章 をご参照ください。 これにより、 [ ] にある座標を変更することで、別の lattice 座標に含まれているセル番号301の領域を指定することができます。 個別に幾つか指定する時はコンマを用い、 101[-1 -1 0, 1 -1 0, 0 0 0] のように書きます。 また、 101[-1:1 -1:1 0] の様に指定した場合は、lattice 座標 \((i,j,k)\) で表現した \(-1 \le i \le 1, -1 \le j \le 1, k=0\) の範囲に含まれる \(3 \times 3 \times 1 = 9\) 個の lattice を意味します。 この場合、9個のタリー結果を分けて出力するのでご注意ください。 もし、一つにまとめた結果を求める場合は、 ( 301 < (101[-1:1 -1:1 0]) ) と記載してください。 ひとつの階層の中で ( ) を用いると、それは括弧内の領域をまとめることを意味します。 他に、 ( u=3 < 101[0 0 0] ) と指定すると、 u=3 に含まれる全てのセル番号が展開されます。 例えば、 u=3 に含まれるセル番号が301と302の場合、この指定方法は reg= ( 301 < 101[0 0 0] ) ( 302 < 101[0 0 0] ) と書いた場合と同じになります。 なお、階層構造をもつ場合も reg=all が使用できますが、最下層でないセルは除かれます。
6.1.1.1. 階層構造の領域と体積の定義¶
次の例題を見てみましょう。
1: mesh = reg
2: reg = (all)
3: ({ 201 - 205 })
4: ( 161 < 160[1:2 3:6 1:1] )
5: ( (201 202 203 204) < (161 162 163 ) )
6: ( ( 90 100 ) 120 < 61 ( 62 63 ) )
上の例のように、 reg= の値は継続行の記号( \ )を使わずに複数行にわたって記述することができます。この場合、次に別のキーワード(この例では volume )が現れるまで、複数行に分けて書かれた値が引き続き reg= の並びとして読み込まれます。
このメッシュ定義文をタリーで用いてエコーを取ると次のものが得られます。
1: mesh = reg # mesh type is region-wise
2: reg = ( all ) ( { 201 - 205 } ) ( 161 < 160[ 1:2 3:6 1:1 ] ) ( (
3: { 201 - 204 } ) < ( { 161 - 163 } ) ) ( ( 90 100 ) 120 < 61
4: ( 62 63 ) )
5: volume # combined, lattice or level structure
6: non reg vol # reg definition
7: 1 10001 8.1000E+01 # ( all )
8: 2 10002 5.0000E+00 # ( { 201 - 205 } )
9: 3 10003 1.0000E+00 # ( 161 < 160[ 1 3 1 ] )
10: 4 10004 1.0000E+00 # ( 161 < 160[ 2 3 1 ] )
11: 5 10005 1.0000E+00 # ( 161 < 160[ 1 4 1 ] )
12: 6 10006 1.0000E+00 # ( 161 < 160[ 2 4 1 ] )
13: 7 10007 1.0000E+00 # ( 161 < 160[ 1 5 1 ] )
14: 8 10008 1.0000E+00 # ( 161 < 160[ 2 5 1 ] )
15: 9 10009 1.0000E+00 # ( 161 < 160[ 1 6 1 ] )
16: 10 10010 1.0000E+00 # ( 161 < 160[ 2 6 1 ] )
17: 11 10011 4.0000E+00 # ( ( { 201 - 204 } ) < ( { 161 - 163 } ) )
18: 12 10012 2.0000E+00 # ( ( 90 100 ) < 61 )
19: 13 10013 1.0000E+00 # ( 120 < 61 )
20: 14 10014 2.0000E+00 # ( ( 90 100 ) < ( 62 63 ) )
21: 15 10015 1.0000E+00 # ( 120 < ( 62 63 ) )
入力では5つの領域の様に見えますが、エコーを見るとタリーを取る領域として15の領域が定義されていることが分かります。 それぞれ単一の領域番号で表されないので、新たに10000番台の番号を付けて、その体積と領域の定義文がエコーされます。 この場合、 [volume] セクションが無いので各セルの体積は1と定義されています。
まず、 ( all ) は、この例題では81個の最下層のセルが定義されているので、この領域の体積は81となっています。 もし最下層のセルの体積が正確に [volume] セクションで定義されていれば、この領域の体積は入力しなくても正確に与えられます。
次に ({ 201 - 205 }) は、201から205までの領域をまとめたものですから、体積として5がエコーされています。 これも [volume] セクションで正確に体積が定義されていれば、この領域の体積は入力しなくてもかまいません。
次に、 ( 161 < 160[1:2 3:6 1:1] ) ですが、これは、160の領域の中に161の領域が lattice として組まれています。 ここでは、lattice 座標の \(i\) に関して1から2、 \(j\) に関して3から6、 \(k\) に関して1の各 lattice に含まれているセル番号161の計8個の領域でタリーを取ることを意味します。 エコーでは、最下層の領域の数1が体積としてエコーされています。 この様な場合は、次に示す volume サブセクションで体積を与えなければなりません。
次は、 ( (201 202 203 204) < (161 162 163 ) ) ですが、これは、各階層に幾つかの領域が記述されていますが、全て括弧で括られてひとつの領域にされているので、全体としてもひとつの領域を表します。 エコーの体積は、最下層の領域の和としているので正しくはありません。 これも volume サブセクションで与えなければなりません。
最後の ( ( 90 100 ) 120 < 61 ( 62 63 ) ) は、各階層に2つずつ独立な領域があるので計4個の領域に分割されます。 それぞれの体積はやはり volume サブセクションで与える必要があります。
Volume サブセクションは、インプットエコーの書式をそのまま使えます。
mesh = reg
reg = 1 2 3 4 ( 5 < 12 ) ( {13 - 17} )
volume
reg vol
1 1.0000
2 5.0000
3 6.0000
4 1.0000
10001 6.0000
10002 5.0000
上の例題では、 reg として、1から4まではそのまま、 ( 5 < 12 ) ( {13 - 17} ) は、10001と10002を用います。 この番号は、一度インプットエコーを取ると得られます。 上の例題より分かるように、インプットエコーの部分をそのままコピーし、体積の値だけを変更すれば済みます。
領域番号( reg )と体積( vol )の順番を変えたいときは、 vol reg とします。 読み飛ばしコラム用の non も使えます。 インプットエコーでは、 non として通し番号が付けられています。 axis = reg の時のタリーの出力の際にはこの番号が X 軸の値として出力されます。
6.1.2. r-z メッシュ¶
r-z スコアリングメッシュの場合、まず、円柱の中心軸の x、y 座標のオフセットを
mesh = r-z
x0 = 1.0
y0 = 2.0
の書式で定義します。 これは省略可能でデフォルト値はゼロです。
次に、
mesh = r-z
r-type = [1-5]
..........
..........
z-type = [1-5]
..........
..........
で始まる各サブセクションによって r と z のメッシュを定義します。 メッシュ定義文は 6.6 章 で説明します。
[t-track] タリーに関しては、既存の r、z メッシュに加え、 \(\theta\) メッシュを指定することができます。 ここで、 \(r, \theta, z\) はそれぞれ円柱座標系における
\(r\): 円の半径
\(\theta\): 円面における角度
\(z\): 円柱の中心軸上の位置
であり、 \(\theta\) を定義する方位角の基線は x 軸です。 [t-track] において \(\theta\) に関するメッシュを指定する際は、 a-type を用いてください。 a-type=1,2,-1,-2 のタイプがありますが、これらの数字が正の場合は角度の単位を余弦で与え、負の場合は degree 単位で与えることになります。 ただし、円柱の定義であるので、0度から360度までしか指定できません。 また、角度のメッシュを加えたことにより、角度を横軸にして出力できるようになりました。 そのために axis として、 rad と deg を指定できます。 rad は radian で、 deg は degree の単位で出力します。
6.1.3. xyz メッシュ¶
xyz スコアリングメッシュの場合、
mesh = xyz
x-type = [1-5]
..........
..........
y-type = [1-5]
..........
..........
z-type = [1-5]
..........
..........
で始まる各サブセクションによって x、y、z のメッシュを定義します。 サブセクションの記載方法は 6.6 章 で説明します。
6.1.4. 四面体メッシュ¶
連続四面体(四面体メッシュ)形状 5.6.4.4 章 を使用している場合にのみ有効で、この体系内の各四面体で物理量をタリーすることができます。 但し、現状では [t-track] 、 [t-deposit] 、 [t-yield] 、 [t-product] 、 [t-dpa] でのみ使用可能です。
書式は、
mesh = tet
reg = 100
のように mesh の指定の次の行で領域番号 reg を指定します。 ここで領域番号として、連続四面体形状を収めた直方体領域を指定してください。 こうすることで、この直方体領域に定義した全ての四面体に対して、個別に物理量がタリーされます。
四面体メッシュ体系を構成する一部の四面体要素の Universe を構成する領域(ユニバース領域)だけを指定したい場合は、階層構造領域の指定と同様に、次のような形式で指定します。
reg = ( 201 202 < 101 )
ここで、201、202は四面体のユニバース領域で、この指定によりセル101に展開される四面体メッシュ体系のうち、201、202のユニバース領域に含まれる四面体に対して、個別に物理量がタリーされます(例 リスト 5.6.14 参照)。 また、ユニバース領域のみを
reg = 201
のように指定することもできます。 2つ以上のユニバース領域を指定する場合は、 (201 202) のように括弧で括る必要があります。 ユニバース領域での指定は、入力ファイル内に四面体メッシュ体系が一つしか定義されていない場合にのみ有効です。
四面体の合計は、代わりに領域メッシュ( mesh=reg )で、ユニバース領域を指定することで、実現できます。 また、四面体の一部をくり抜いて使用している場合、四面体の体積を自動で計算しているため、正しい物理量が導出されない恐れがあります。 この場合も領域メッシュ( mesh=reg )を使用して回避してください。
6.2. エネルギーメッシュ¶
タリーのエネルギーメッシュは
e-type = [1-5]
..........
..........
で始まる e-type サブセクションによって定義します。 単位はMeV(ただし、粒子エネルギーを定義する場合は、 iMeVperN や e-unit によりMeV/nやnmに切り替わる)。 [t-deposit2]では、 e1-type , e2-type で二つのエネルギーメッシュを定義します。 サブセクションの記載方法は 6.6 章 で説明します。
6.3. LETメッシュ¶
タリーのLETメッシュは
l-type = [1-5]
..........
..........
で始まる l-type サブセクションによって定義します。 単位はkeV/um。 サブセクションの記載方法は 6.6 章 で説明します。
6.4. 時間メッシュ¶
タリーの時間メッシュは
t-type = [1-5]
..........
..........
で始まる t-type サブセクションによって定義します。 単位はnsecです。 サブセクションの記載方法は 6.6 章 で説明します。
6.5. 角度メッシュ¶
[t-cross], [t-product] タリーで用いる角度メッシュは
a-type = [1, 2, -1, -2]
..........
..........
で始まる a-type サブセクションによって定義します。 この定義により、余弦(cos)もしくは角度(degree)を定義します。 a-typeを正で定義したときは余弦(cos)、負で定義したときは角度(degree)を表します。 サブセクションの記載方法は 6.6 章 で説明します。
6.6. メッシュの定義方法¶
e-type, t-type, x-type, y-type, z-type, r-type, a-type, l-type で始まる8種類のサブセクションを記載することで、各メッシュを定義します。 最初の一文字を除くと全て共通なので、ここでは e-type を例に解説します。 ne を nx, ny, nz, ...、 emin を xmin, ymin, zmin, ... 、の様に読み換えてください。
定義したメッシュの最小のビンに emin の値自身は含まれます。 一方、最大のビンに emax の値自身は含まれません。
6.6.1. メッシュタイプ¶
メッシュの指定の仕方は5種類あり、それを e-type = [1-5] で指定します。1 から 5 番までのそれぞれのメッシュタイプは以下となります。
メッシュタイプ |
内容 |
|---|---|
1 |
群数、分点をデータで与える。 |
2 |
群数と最小値、最大値を与え、線形で等分点が与えられる。 |
3 |
群数と最小値、最大値を与え、対数で等分点が与えられる。 |
4 |
メッシュ幅と最小値、最大値を与え、線形で等分点が与えられる。このとき、分点の最大値は与えた最大値もしくは最大値を超える最小の値となるように群数が決定される。 |
5 |
最小値、最大値、メッシュ幅の対数値とを与え、対数で等分点が与えられる。このとき、分点の最大値は与えた最大値もしくは最大値を超える最小の値となるように群数が決定される。 |
ただし、 a-type 即ち、角度のメッシュでは、1, 2 (-1, -2) のメッシュタイプしか使えません。
[t-cross] で z-type=1 とした場合のみ、群数 nz を0としてデータ点を1つだけ指定することが可能です。 この場合、z=(データ点)とする面のみがタリー面として設定されます。
以下に、それぞれのメッシュタイプのデータの定義の書式を示します。
6.6.2. e-type = 1 の場合¶
書式は、
e-type = 1
ne = ngroup
data(1) data(2) data(3) data(4)
data(5) data(6) data(7) data(8)
.........
.........
data(ngroup+1)
です。 ngroup は、その次の行から与える data の群数を表します。 data には、その数に 1 を加えた個数の値を並べます。 この際、継続行のシンボル無しに複数行にまたがっても自動判別します。
6.6.3. e-type = 2, 3 の場合¶
次に群数、最小値、最大値を次の様な書式で与えます。
e-type = 2, 3
ne = ngroup
emin = minvalue
emax = maxvalue
ngroup はエネルギー群数を表します。 最小値 (minvalue) から最大値 (maxvalue) までを、線形(e-type = 2 の場合)または対数(e-type = 3 の場合)に等分割してメッシュを定義します。
6.6.4. e-type = 4 の場合¶
次に、メッシュ幅、最小値、最大値を次の様な書式で与えます。
e-type = 4
edel = width
emin = minvalue
emax = maxvalue
最小値 (minvalue) から最大値 (maxvalue) までを、 width をメッシュ幅として、線形で分割する。
6.6.5. e-type = 5 の場合¶
次に、メッシュ幅、最小値、最大値を次の様な書式で与えます。
e-type = 5
edel = widthlog
emin = minvalue
emax = maxvalue
この場合、メッシュ幅は対数上での幅を意味します。 即ち widthlog は \(\log\left(\frac{M_{i+1}}{M_i}\right)\) で定義されます。
6.7. 他のタリーパラメータ¶
6.7.1. partパラメータ¶
タリーの中で粒子を指定する時は、
part = proton neutron pion+ 3112 208Pb
のように空白で区切って定義するか、
part = proton
part = neutron
part = pion+
part = 3112
part = 208Pb
のように、パラメータを繰り返すことも出来ます。 粒子名の表式は 表 4.7.1 を参照してください。 kfコード番号での指定も可能です。
part = all
と定義すると、粒子すべての和を表わします。
複数の粒子をひとつのグループとしてタリーしたいときは、次のように ( ) が使えます。 ( ) の中の粒子は、最大6個まで指定できます。 ただし、kfコード番号を ( ) で使用する場合は、最後のkfコード番号と ) の間にスペースが必要です。 スペースが無い場合は、 part パラメータの指定が不正とのエラーメッセージが出力されます。
part = ( proton neutron ) all pion+ 3112 208Pb
この場合、protonとneutronを合わせたものが、最初のグループとして出力されます。 2番目は、全ての粒子の和です。 全体として5種類の粒子についての出力になります。 原子核は、208Pbのように質量数を指定すればその核、Pbのように質量数を指定しなければ、Pbの同位体全体を指定することになります。
粒子名の前に負符号をつけて指定すると、全体から指定された粒子の寄与を除いた結果が出力されます。 kfコード番号での指定の場合は、 ( ) を使って、 ( ) の前に負符号をつけるように指定してください。 複数の粒子の寄与を除いた結果をタリーしたい場合は ( ) を使ってグループを作り、その ( ) の前に負符号を付けてください。 ( ) 内で、負符号により指定粒子の寄与を除く指定はできません。 part パラメータの指定が不正とのエラーメッセージが出力されます。
part = -proton -(proton alpha) -(2112) -(11 -11)
この場合、1番目はprotonの寄与を除いたもの、2番目はprotonとneutronの寄与を除いたもの、3番目は中性子(2112)を除いたもの、4番目は電子(11)と陽電子(-11)の寄与を除いたものが出力されます。
6.7.2. axisパラメータ¶
出力データのx軸を定義します。 axis の種類は、タリーの種類とタリーのメッシュ型によりますが、
eng, reg, x, y, z, r, t, xy, yz, zx, rz,
cos, the, mass, charge, chart, dchain,
let, t-eng, eng-t, t-e1, e1-t, t-e2, e2-t, e12, e21
があります。
axis = eng
のように定義します。
ひとつのタリーで複数の axis が定義できます。
axis = eng x y
とするか、
axis = eng
axis = x
axis = y
のように表わすことも出来ます。 ひとつの axis に対して、ひとつのファイルに結果が出力されます。 従って、複数の axis を定義した場合は、次のファイルパラメータで同数のファイル名を定義する必要があります。 なお、[t-yield]では、1つのタリーセクションに1つの axis しか指定できません。 複数の axis に対して残留核収率を計算したい場合は、複数の[t-yield]タリーを作成してください。 これは、統計誤差を正しく計算するためにバージョン2.50以降についた制限です。
6.7.3. samepageパラメータ¶
画像出力ファイルの同じページに表示するデータの種類を指定します。 指定可能なパラメータは、 axis で定義できるパラメータです。 デフォルトは part で、その場合、 part パラメータで指定した複数の粒子に対する結果が同じページに出力されます。 samepage には、 axis で指定したものとは別のパラメータを指定する必要があります。 samepage で指定したデータのビン数が20を超える場合、epsファイルには1から20ビン目までしか表示されないのでご注意ください。 [t-yield]タリーの他、幾つかのタリーでは使用できません。
6.7.4. fileパラメータ¶
出力ファイル名を定義します。 書式は、
file = file.001 file.002 file.003
のようにファイル名を書きます。 もし、PHITSのインプットファイルがあるディレクトリとは別の場所に出力させたい場合は、 相対パスか絶対パスの形で指定してください。 ただし、.epsや.vtkの拡張子をもつ名前は指定しないようにしてください。 axis を複数指定したときは、その数だけファイル名を指定します。 このとき
file = file.001
file = file.002
file = file.003
のように一行にひとつずつ書くこともできます。
6.7.5. resfileパラメータ¶
再開始計算時に使用する乱数を把握するため、以前の計算で出力されたタリーファイル名を指定します。 書式は
resfile = file.out
のようにファイル名を書きます。 もし、インプットファイルがあるディレクトリとは別の場所にあるファイルを指定する場合は、 相対パスか絶対パスの形で指定してください。 複数の file を指定した場合でも、 resfile は1つで十分です。 2つ以上指定した場合、先に書いたファイルが優先されます。 resfile のデフォルトは、 file です。 その場合、過去タリーファイルから結果を読み込んで、新しい結果を加えて同じファイルに上書きします。
6.7.6. unitパラメータ¶
出力の単位を定義します。 通常番号で次の様に定義します。
unit = number
番号とその単位の内容は、各タリーの説明で解説します。
6.7.7. factorパラメータ¶
出力の規格化定数を定義します。 [t-gshow]タリーでは、境界線の太さを指定します。 次の様に定義します。
factor = value
正の値だと、出力の物理量にこの定数が掛けられます。 負の値(例:-c)を指定すると、タリー中の最大値がcとなる様に規格化されます。
6.7.8. outputパラメータ¶
出力する情報の種類を定義します。 次の様に定義します。
output = name of output
詳細は、各タリーの説明で行います。
6.7.9. infoパラメータ¶
出力するタリー出力で、詳細情報を出力するかどうかのオプションです。 通常、0 か 1 で定義します。
info = 0, 1
6.7.10. titleパラメータ¶
タリー出力に表示されるタイトルを定義します。
title = title of the tally
省略可能です。 省略された場合、デフォルト値が入ります。
6.7.11. ANGELパラメータ¶
タリー出力で、ANGELのパラメータを追加します。
angel = xmin(1.0) ymin(1.3e-8)
ここで定義したパラメーターは、タリー出力の中で
p: xmin(1.0) ymin(1.3e-8)
と記載され、横軸と縦軸の最小値をそれぞれ指定した値に変更します。
ANGELについては、13.1 章 をご覧ください。
6.7.11.1. SANGEL パラメータ¶
タリー出力において、ANGEL 用のパラメータを追加できるようになります。ANGEL パラメータ定義文では p: で始まる ANGEL 用パラメータしか定義できませんが、本定義文を使用することで任意の ANGEL 用パラメータを定義できるようになります。
例えば、infl: パラメータを定義することで、タリー出力ファイルに対して実験値などをまとめた外部ファイルを挿入し、計算値と比較した結果を図示することができます。
書式は、sangel= でタリー出力に書き出す行数を指定し、その次の行からその行数だけパラメータを加えます。例えば、
sangel = 2
infl:{exp.dat}
w: ($\theta=$ 0 deg) / X(10) Y(100)
とすることで、exp.dat にまとめた実験値を図示すると共に、X=10, Y=100 の座標位置に \(\theta=0\) deg というコメントを加えることができます。
バージョン 3.31 以降、デフォルトでは sangel 中に infl が使用できなくなりました。使用する場合は、 $RWT=0 を最初のセクションが始まる前に追加してください。
6.7.12. 2d-typeパラメータ¶
タリー出力で、 axis = xy などの2次元表示を選択したときの、2次元データの表示のオプションです。番号で指定します。 ただし、 rshow オプションがあるタリーでは、意味を持ちません。
2d-type = 1, 2, 3, 4, 5, 6, 7
2d-type = 1, 2, 3, 6, 7
これは、データの並びがFortranの書式で書くと
( ( data(ix,iy), ix = 1, nx ), iy = ny, 1, -1 )
で、1行に10個のデータが入り、ANGEL用のヘッダーが付きます。 ヘッダーは、1は等高線、2はクラスタープロット、3はカラープロットです。 6はクラスターと等高線です。 7はカラープロットと等高線です。
2d-type = 4
これは、データの並びがFortranの書式で書くと
do iy = ny, 1, -1
do ix = 1, nx
( x(ix), y(iy), data(ix,iy) )
end do
end do
で、1行に x(ix), y(iy), data(ix,iy) の 3個のデータが入ります。
2d-type = 5
これは、データの並びがFortranの書式で書くと
y/x ( x(ix), ix = 1, nx )
do iy = ny, 1, -1
( y(iy), data(ix,iy), ix = 1, nx )
end do
で、1行に nx + 1 個のデータが並び、全部で ny + 1 行です。 Excel 等に取り込むデータとして便利です。
6.7.13. gshowパラメータ¶
[t-gshow], [t-rshow] 以外のタリーで用いることができます。 タリーのメッシュがxyzメッシュ、axisがxy, yz, xz で、かつ 2d-type = 1,2,3,6,7 のANGELの出力を想定したタリーで、これを指定すると、出力の画面に領域の境界線、また物質番号、領域番号、LAT番号が表示されます。
gshow = 0, 1, 2, 3, 4, 5
0 で表示無し、1 は境界線の表示、2 は境界線と共に物質番号、3 は境界線と共に領域番号、4 は境界線と共に領域番号とLAT番号、5はピクセル形式で物質色、を表示します。 物質番号、領域番号、LAT番号を表示させるときに、resolを使って分解能をresol倍にすると、番号の表示が乱れますので、番号を表示させるときは、resolでなくメッシュの個数を増やして分解能を上げてください。
パラメータセクションで、icntl = 8 とすることにより、実際の計算をすることなしに、タリーを設定した領域を事前に見ることができます。 icntl = 8 とすると、輸送計算はせずに、xyzメッシュ、xy, yz, zx, axis のタリーで gshow = 1, 2, 3, 4, 5 が指定してあるものの領域を指定のファイルに書き出します。 その時、物質毎に色分けします。 この機能を使い、大きい計算の前に、タリーの領域の確認、xyzメッシュの分解能の適否を確認することをお勧めします。
6.7.14. rshowパラメータ¶
[t-cross]と[t-gshow]以外のタリーで用いることができます。 タリーの mesh が reg 及び tet メッシュの場合に利用でき、領域毎及び四面体要素毎に求めた物理量の大きさに応じた色を幾何形状表示させた体系に付与します。 axis は xy, yz, xz のどれかを指定する必要があり、更に rshow パラメータの下に xyz のメッシュパラメータが必要となります。 rshow の値を変えることで、境界線、物質番号、領域番号を表示させることができます。
rshow = 1, 2, 3
x-type = [2,4]
..........
..........
y-type = [2,4]
..........
..........
z-type = [2,4]
..........
..........
0 で表示無し、1 は境界線の表示、2 は境界線と共に物質番号、3 は境界線と共に領域番号を表示します。 0 の時は、xyzメッシュパラメータは、不必要なのでコメントアウトして下さい。 物質番号、領域番号を表示させるときに、resolを使って分解能をresol倍にすると、番号の表示が乱れますので、番号を表示させるときは、resolでなくメッシュの個数を増やして分解能を上げてください。 ただし、 gslat が未設定の状態では、同じ物質(rshow=2)や同じセル(rshow=3)の間で境界線を描画せず、統合的に表示するので、正しい領域毎および四面体要素毎の値で表示されない恐れがあります。 そこで、 gslat=1 を同時に指定することを推奨します。
reg 及び tet メッシュでこのオプションを付けると、領域ごとの出力はありません。 従って、計算の後に図の体裁や最大値最小値の調整などは、元のデータがありませんからできません。 このオプションを付ける時は、 axis=xy,yz,zx で用いるわけですが、その他に axis=reg 或いは =tet も加えて別ファイルに領域の物理量のデータを保存することをお勧めします。 そのデータと、[t-rshow]タリーを用いることにより、再度加工したデータを元に表示することが可能となります。
パラメータセクションで、icntl = 10 とすることにより、実際の計算をすることなしに、タリーを設定した領域を事前に見ることができます。 icntl = 10 とすると、輸送計算はせずに、regメッシュ、xy, yz, zx,axis のタリーで rshow = 1, 2, 3 が指定してあるものの領域を指定のファイルに書き出します。 その時、物質毎に色分けします。 この機能を使い、大きい計算の前に、タリーの領域の確認、xyzメッシュの分解能の適否を確認することをお勧めします。
6.7.15. x-txt, y-txt, z-txtパラメータ¶
ANGEL表示のx, y, z 軸のテキストをデフォルトから変えたい時に用います。 これらのテキストは、ANGELパラメータでは、変えられません。
x-txt = テキスト
y-txt = テキスト
z-txt = テキスト
6.7.16. volmatパラメータ¶
volmat パラメータは、xyzメッシュでメッシュが領域境界をまたいでいる時の体積補正をするものです。 これが有効になるのは、xyzメッシュでかつmaterialの指定がある場合です。 領域をまたいだメッシュの体積を、メッシュサイズから与えるのではなく、指定されたmaterialを含む体積をモンテカルロ的に計算します。 その時のスキャンは、各軸に平行な1辺当たりvolmat数の軌跡で計算します。 この数をあまり大きく取るとメッシュ数にもよりますが、計算時間が膨大になることがありますので注意して下さい。 volmatを負の数で指定すると、強制的に全てのxyzメッシュをスキャンします。 正の場合は、メッシュの8頂点が同じ物質ならスキャンしません。
6.7.17. epsoutパラメータ¶
epsout = 1 を指定すると、出力ファイルをANGELで処理したepsファイルを作成します。 ファイル名は出力ファイルの拡張子を epsに変えたファイル名です。 パラメータセクションで itall = 1 を指定していれば、バッチ毎にタリーの結果の変化を自動的に画面上で確認できます。
6.7.18. カウンターパラメータ¶
[counter]セクションで定義したカウンターを用いて、タリーで集める物理量に制限を加えることができます。 各カウンターごとに、最小値と最大値を ctmin(i), ctmax(i) で定義します。 i は、カウンター番号、1から3です。 デフォルト値は最小値が-9999、最大値が9999です。 複数のカウンターを用いる時は、それらの条件の共通部分となります。
また、あるヒストリー中に発生する全粒子のカウンター値の最大値を使って制限を加えることも可能です。
その場合は、 chmin(i), chmax(i) を使います。
この機能を使えば、特定のイベントが発生した場合に線源発生まで遡ってタリーすることが可能となります。
詳しくは phits/sample/misc/history/counter フォルダをご参照ください。
ただし、この最大カウンター制限機能は、バッチ分散モード( istdev=1 )では動作しません。
また、[weight window]などの分散低減法を使用した計算やイベントジェネレーターモードを使用しない計算の場合は、ヒストリーカウンターの機能が適切に動作しない可能性がありますのでご注意ください。
6.7.19. resol 分解能、width 線太さパラメータ¶
resol を使い、gshow、rshow、3dshowの表示の時、指定したxyzのメッシュを固定したまま、境界線を求める分解能を上げることができます。 デフォルトは1で、xyzのメッシュの分解能と同じです。 resol = 2 とすると各辺2倍のメッシュになります。 xyzメッシュのタリーで、境界線の精度だけ上げるのに便利です。 また、3dshowの時も、荒い精度で表示を確認してから、 resol を大きくして最終的なきれいな図を得ることができます。 resol を大きくしてもメモリーは変化しません。 ただし、物質番号、領域番号、LAT番号を同時に表示させるときには、resolを使って分解能をresol倍にすると、番号の表示が乱れますので、番号を表示させるときは、resolでなくメッシュの個数を増やして分解能を上げてください。
width は、gshow、rshow、3dshowの表示の時の線の太さを定義します。 デフォルトは、0.5です。
6.7.20. trcl 座標変換¶
r-z、xyzメッシュの座標をtrclにより座標変換します。 書式は以下のように2通りあります。
trcl = number
trcl = O1 O2 O3 B1 B2 B3 B4 B5 B6 B7 B8 B9 M
最初の書式は、[transform]セクションで定義した座標変換番号です。
次の書式は、この定義の中で座標変換を定義します。
[transform]と同じように13個の数字で定義します。
一行に収まらない場合は、複数の行にわたって定義できます。
その時は自動認識しますので、行末の継続行の記号 ¥ は必要ありません。
ただし、継続行は先頭に12個以上の空白が必要です。
r-z、xyzメッシュの他に、3dshowのタリーでboxを定義するときにも、trclによる座標変換が使えます。 書式は[t-3dshow]のところで示します。
6.7.21. Dump機能で出力する粒子情報¶
dump パラメータを定義できるタリー([t-track], [t-cross], [t-point], [t-deposit], [t-product], [t-dpa], [t-time], [t-interact]) [2] では、タリーされた各粒子の情報を出力することができます。 dump パラメータで出力する情報の数(正値の場合はバイナリー、負値の場合はアスキーデータで出力)を指定した後、次行で出力する粒子情報番号( 表 6.7.1 参照)を定義します。
dump パラメータを定義されたファイルからは少なくとも2つのファイルが出力されます。
通常のタリーの結果は、 file 定義文で指定した名前のファイルにテキスト形式で書き出されます。
一方、出力する粒子情報は、 file 定義文で指定した名前の拡張子の直前に _dmp を付けた名前のファイルに書き出されます。
また、メモリ分散型並列計算時には使用する並列PE (Processor Element) 数-1 個のファイルを作成します。
データをdump するファイルの名前の最後にPE番号をつけたファイルが作られ、各PE は対応するファイルにのみデータの書き出しと読み込みを行います。
メモリ共有型並列計算を実行する場合、本機能によるdump ファイルの作成と dumpall によるイベント情報の書き出しは共存できませんのでご注意ください。
粒子情報番号 |
表示記号 |
説明 |
|---|---|---|
1 |
kf |
|
2 |
x |
現在粒子もしくは生成粒子のx座標 (cm) |
3 |
y |
現在粒子もしくは生成粒子のy座標 (cm) |
4 |
z |
現在粒子もしくは生成粒子のz座標 (cm) |
5 |
u |
現在粒子もしくは生成粒子のx方向ベクトル |
6 |
v |
現在粒子もしくは生成粒子のy方向ベクトル |
7 |
w |
現在粒子もしくは生成粒子のz方向ベクトル |
8 |
e |
現在粒子もしくは生成粒子のエネルギー(単位は iMeVperN や e-unit に準拠) |
9 |
wt |
現在粒子もしくは生成粒子のウェイト |
10 |
tm |
現在粒子もしくは生成粒子の時間 (ns) |
11 |
c1 |
現在粒子もしくは生成粒子のカウンター1値 |
12 |
c2 |
現在粒子もしくは生成粒子のカウンター2値 |
13 |
c3 |
現在粒子もしくは生成粒子のカウンター3値 |
14 |
sx |
現在粒子もしくは生成粒子のスピンのx方向ベクトル |
15 |
sy |
現在粒子もしくは生成粒子のスピンのy方向ベクトル |
16 |
sz |
現在粒子もしくは生成粒子のスピンのz方向ベクトル |
17 |
name |
現在粒子もしくは生成粒子の衝突回数(開発者向け用途) |
18 |
nocas |
バッチ中のヒストリー番号 |
19 |
nobch |
バッチ番号 |
20 |
no |
該当ヒストリーにおけるカスケードID(開発者向け用途) |
21 |
kf0 |
過去粒子もしくは親粒子の種類(kfコード、表4参照) |
22 |
x0 |
過去粒子もしくは親粒子のx座標 (cm) |
23 |
y0 |
過去粒子もしくは親粒子のy座標 (cm) |
24 |
z0 |
過去粒子もしくは親粒子のz座標 (cm) |
25 |
u0 |
過去粒子もしくは親粒子のx方向ベクトル |
26 |
v0 |
過去粒子もしくは親粒子のy方向ベクトル |
27 |
w0 |
過去粒子もしくは親粒子のz方向ベクトル |
28 |
e0 |
過去粒子もしくは親粒子のエネルギー(単位は iMeVperN や e-unit に準拠) |
29 |
wt0 |
過去粒子もしくは親粒子のウェイト |
30 |
tm0 |
過去粒子もしくは親粒子の時間 (ns) |
31 |
tv |
タリー値(そのイベントによりタリーに加えられる値) |
32 |
rec |
|
33 |
cel |
現在粒子もしくは生成粒子座標の領域番号 |
34 |
mat |
現在粒子もしくは生成粒子座標の物質番号 |
例えば、
dump = 9
1 8 9 2 3 4 5 6 7
と定義した場合、バイナリー形式で kf e wt x y z u v w の順番で出力されます。 [t-product]及び[t-interact]を除くタリーでは、現在と1つ前のステップ(過去)の粒子情報からタリー値を計算するので、それらの情報が粒子情報番号1-17及び21-30にそれぞれ出力されます。 一方、[t-product]及び[t-interact]では、反応後に生成した粒子と親粒子の情報が粒子情報番号1-17及び21-30にそれぞれ出力されます。 ただし、粒子がカットオフされた場合や線源として発生した場合は、ID=1-10とID=21-30の情報は等しくなります。
[t-deposit]かつ output = deposit 及び[t-interact]かつ MorP = prob の場合は、粒子輸送時ではなく各ヒストリー終了時にタリーが呼ばれますので、粒子情報番号18(ヒストリー番号)、19(バッチ番号)、及び31(タリー値=最初にイベントに寄与した粒子のウェイト)以外は出力することができません。 また、それらの情報の後に、各領域の付与エネルギーもしくは反応数が出力されます。例えば、[t-deposit]かつ output = deposit で
dump = -3
18 19 31
と定義した場合、アスキー形式で nocas nobch tv 各領域の付与エネルギー の順番に1行スペース区切りで出力されます。 ただし、partで複数の粒子を指定しても、最初に指定された part ([t-deposit]の場合は強制的に all になる)に対する結果のみしか出力されません。 また、 material や t-type を指定しても、合計値のみ出力されます。
粒子情報番号31番で出力されるタリー値とは、そのイベントでタリー結果に加算される値で、現在粒子ウェイト( wt ) に[t-track]の場合は現在と過去粒子間の距離(飛跡長)、[t-cross]かつ output = flux の場合は \(1/\cos\theta\) 、[t-point]の場合はタリー点に加算されるフラックス、[t-deposit]の場合は付与エネルギー、[t-dpa]の場合はDPA値、それ以外の場合は1を乗じた値となります。 粒子情報番号32番で出力される反応識別番号は、 表 6.7.2 および 表 6.7.3 に示す大分類・小分類番号に基づき、 大分類番号×1000+小分類番号 で決定されます。 例えば、大分類が核反応、小分類が弾性散乱(MT=2)の場合、反応識別番号は2002となります。
大分類 |
説明 |
|---|---|
0 |
反応以外(粒子の移動、線源発生など) |
1 |
粒子崩壊 |
2 |
核反応 |
3 |
原子反応 |
4 |
飛跡構造解析モードでの反応 |
大分類 |
小分類 |
説明 |
|---|---|---|
1 |
0 |
粒子崩壊 |
2 |
MT番号 [4] |
核反応。MT番号に分類できない反応の小分類は0となります。 |
3 |
0 |
その他の原子反応 |
3 |
1 |
弾き出し電子(δ線)生成 |
3 |
2 |
原子蛍光X線生成 |
3 |
3 |
オージェ電子生成 |
3 |
4 |
制動放射線生成 |
3 |
5 |
光電効果 [5] |
3 |
6 |
コンプトン散乱 |
3 |
7 |
電子陽電子対生成 [6] |
3 |
8 |
陽電子消失 |
3 |
9 |
レイリー散乱 |
3 |
10 |
光学光子(Optical photon)の反応 |
4 |
0 |
その他の飛跡構造解析反応 |
4 |
1 |
弾性散乱 (elastic scattering) |
4 |
2 |
電離 (ionization) |
4 |
3 |
電子的励起 (electronic excitation) |
4 |
4 |
解離性電子付着 (dissociative electron attachment) |
4 |
5 |
振動励起 (vibration excitation) |
4 |
6 |
フォノン励起 (phonon excitation) |
4 |
7 |
回転励起 (rotation excitation) |
4 |
8 |
プラズモンによる励起 (plasmon excitation) |
4 |
9 |
電子捕獲 (electron capture) |
4 |
10 |
電子剥ぎ取り (electron stripping) |
6.8. 複数のタリー結果の統合機能¶
Sumtally機能を使うことにより、複数のタリー結果を足し合わせることができます。足し合わせの方法は2種類あり、手動で並列計算を実行するために各タリー結果のヒストリー数を考慮して足し上げる方法と、各タリー結果に任意の重み付けをして加重平均を求める方法があります。前者は、並列計算が利用できず、限られた計算資源を有効に利用したい場合に役立ちます。後者は、例えば複数の線源による計算を行う際、それらの強度を任意に変えた場合の結果を、計算をやり直さずに求めることができます。
Sumtally機能が動作する条件は次の3つです。
[parameters] セクションにおいて icntl=13 とする。 [7]
足しあわせたいタリー結果の条件( mesh 、 axis 、 part など)が一致していること。
足しあわせたいタリー結果の条件が書かれたタリーセクションにおいて、sumtallyサブセクションを設定する。 [8]
Sumtallyサブセクションが設定されていても、 [parameters] セクションで icntl=13 となっていなければその内容は無視されます。 [9]
この機能の具体的な利用方法については、 \phits\utility\sumtally フォルダにある資料やサンプルインプットをご参照ください。
Sumtallyサブセクションは、 sumtally start と sumtally end で挟んだ領域で設定します。本サブセクション内のユーザー定義定数 ci ( \(i=1\sim 99\) )は無視されるのでご注意ください。
Sumtallyサブセクションで使用できるパラメータは 表 6.8.1 の通りです。
name |
値 |
説明 |
|---|---|---|
isumtally = |
1(省略時), 2 |
Sumtally機能の計算方法。 1: 手動並列計算用。 2: 加重平均計算。 |
nfile = |
数 |
タリーファイル数。 |
(次行) |
file name 数値 |
タリーファイル名、重み付けの値。 isumtally=2 の場合は自動的に規格化されます。 |
sfile = |
file name |
sumtally機能で足しあわせた結果の出力ファイル名。 |
sumfactor = |
(省略可、D=1.0) |
規格化定数。 |
isumtally=1 の場合は手動で並列計算を実行することができます。例えば、 maxcas=100, maxbch=10 で計算した結果 result-1.out と maxcas=100, maxbch=20 で計算した結果 result-2.out がある場合、次のようにsumtallyサブセクションを設定することで maxcas=100, maxbch=30 の条件で計算した結果 result-s.out を得ることができます。
1: sumtally start
2: isumtally = 1 $(D=1) sumtally option, 1:integration, 2:weighted sum
3: nfile = 2 $ number of tally files
4: result-1.out 1.0
5: result-2.out 1.0
6: sfile = result-s.out $ file name of output by sumtally option
7: sumfactor = 1.0 $ (D=1.0) normalization factor
8: sumtally end
ただし、乱数の重複を避けるために、 result-2.out の計算を実行する際は [parameters] セクションにおいて irskip=-1000 を設定してください。また、足し合わせるファイル名の右で設定する重み付けの値は、基本的に1としてください。 isumtally=1 の場合、重み付けの値を1より変更することで、各タリー結果を求めた際のソースウエイトの平均値を変えることになります( [source] セクションで wgt を変更した場合と同じ)。なお、 isumtally=1 で得られたタリー結果に対しては再開始計算を実行することが可能です。この場合は nfile 以下で指定するタリーファイルの内、一番下のファイルにある乱数が用いられます。
isumtally=2 の場合、次の計算式により加重平均値 \(\bar{X}\) を求めます。
ここで、 \(F\) が sumfactor で指定する規格化定数、 \(N\) が nfile で指定するタリーファイル数、 \(\bar{X}_j\) が \(j\) 番目のタリーファイルの結果、 \(r_j\) が \(j\) 番目のタリーファイルの重み付けの値です。 \(r\) は \(r=\sum_{j=1}^N r_j\) で計算しており、重み付けの値 \(r_j\) を変えることで、各タリー結果の相対的な強度を任意に与えることができます。標準偏差 \(\sigma_X\) は、 \(j\) 番目のタリー結果の標準偏差を \(\sigma_{X_j}\) とし、
により求めています。 isumtally=2 は、例えば、ある標的に対して左右から違う量の放射線を照射した結果を求めたい時に利用できます。左から照射した結果が result-l.out 、右から照射した結果が result-r.out であった場合、2:3の割合で照射した結果は次のような設定で計算することができます。
1: sumtally start
2: isumtally = 2 $(D=1) sumtally option, 1:integration, 2:weighted sum
3: nfile = 2 $ number of tally files
4: result-l.out 2.0
5: result-r.out 3.0
6: sfile = result-s.out $ file name of output by sumtally option
7: sumfactor = 5.0 $ (D=1.0) normalization factor
8: sumtally end
この条件と同じシミュレーションはマルチソースの機能を利用することで実行可能です。 しかし、照射割合を変えるなど、色々な条件の計算を調べたい場合は、 isumtally=2 を利用するのが便利です。 なお、重み付けの値は、足し合わせるタリー結果の相対的な割合にしか影響しませんのでご注意ください。 絶対値を変える場合は sumfactor の値を変更します。 例えば、本例題の場合は、result-l.outを2倍し、result-r.outを3倍して足し合わせたいので、sumfactorを5にします。 また、 isumtally=2 の場合は、乱数等の再開始計算に必要な情報は出力されず、再開始計算ができないようになっています。
6.9. 複数のタリー結果の解析機能¶
前セクションの sumtally 機能は複数のタリー結果の単純な加重和を計算する機能ですが、より複雑な解析を行いたい場合は anatally 機能を使ってください。例えば、粒子線治療における生物学的線量を吸収線量の絶対値を考慮して計算したり、物質密度がもつ誤差が計算結果に与える影響を系統的不確かさとして評価することが可能です。
本機能は、通常の輸送計算により得られた複数のタリー結果を解析するものです。動作方法として次の2つがあります。
手動で通常の輸送計算を実行した後、その結果得られたタリーファイルを指定して anatally 機能を動作させる。( リスト 6.9.1 参照)
autorunスクリプトを利用して、自動的に通常の輸送計算と anatally 機能の動作を通して実行する。( 6.9.2 章 参照)
後者の方法は、基本的に上の例にある系統的不確かさを評価する時に使用します。前者の方法でも評価できますが、入力値を多数変動させて不確かさを評価する場合は後者の方が便利です。
Anatally 機能自体は、 [parameters] セクションにおいて icntl=17 とすることで動作します。ただし、適切に動作させるためには次の条件を満たす必要があります。
解析の対象となる複数のタリーが mesh 、 axis 、 part やエネルギー、空間等の分割数(ビン数)について同じ条件で得られていること。
解析したいタリー結果のファイル名等をまとめた [anatally] セクションが設定されていること。
上のタリー結果を出力したタリーセクションにおいて、 anatally start と anatally end のみの anatally サブセクションが設定されていること。
[anatally] セクションは、 icntl=17 の時のみ有効となります。その際、anatally サブセクションは [anatally] と [t-track] などのタリーセクションの2箇所に必要です。前者では解析したいファイル名等を記載し、後者では中身のない( anatally start と anatally end のみの)サブセクションを記載します。(なお、 autorun スクリプトを利用する場合は、 icntl=16 とし、 [anatally] は作成せず、解析したいファイル名など 表 6.9.1 にあるパラメータはタリーセクション中の anatally サブセクションにまとめてください。)
Anatally サブセクションは、 anatally start と anatally end で挟んだ領域で設定します。本サブセクション内のユーザー定義定数 ci ( \(i=1\sim 999\) )は無視されるのでご注意ください。
Anatally サブセクションで使用できるパラメータは 表 6.9.1 の通りです。なお、現在のバージョンでは、 icntl=16,17 の場合に、 6.10 章 にある itall=3 の場合に指定できる ix 、 iy 、 iz 、 ipart 等のパラメータは利用できません。
name |
値 |
説明 |
|---|---|---|
ianataldchain = |
(省略可、D=0) |
[t-dchain] のタリー結果を扱うときのオプション。
0: [t-dchain] のタリー結果を扱わない。
1: [t-dchain] のタリー結果を扱う。
[t-dchain] セクションで file パラメータで指定したファイルを指定することにより、DCHAIN 用の出力ファイル( |
manatally = |
0, 1(省略時) |
anatally機能の計算方法。
0: ユーザー定義 anatally( |
nfile = |
数 |
タリーファイル数。 |
(次行) |
file name |
タリーファイル名。 |
sfile = |
file name |
anatally機能で解析した結果の出力ファイル名。 |
1: [t-track]
.........
.........
2: anatally start
3: anatally end
.........
.........
4: [anatally]
5: anatally start 1
6: manatally = 0 $(D=1) anatally option, 0:user-defined anatally, 1:anova
7: nfile = 2 $ number of tally files
8: result-1.out
9: result-2.out
10: sfile = result-a.out $ file name of output by anatally option
11: anatally end 1
この例では、通常の輸送計算( icntl=0 の計算)で得られた [t-track] のタリーファイル result-1.out と result-2.out を使用し、ユーザー定義タリーによって計算した結果を result-a.out に出力します。 [anatally] セクション中の anatally start と anatally end の後にある数字は anatally サブセクションの ID 番号です。解析したいタリーファイルのパラメータ( mesh 、 axis 、 part など)が書かれたタリーセクションが、そのインプットファイルにおいて、何番目のタリーセクションなのかを ID 番号として書いてください。上の例で、もし [t-track] より上に1つ別のタリーセクションが書かれていた場合は、 [anatally] セクションにおいて、 anatally start と anatally end の後には 2 と記載してください。
6.9.1. ユーザー定義anatally機能¶
ユーザー定義 anatally( usranatal.f )に書かれたプログラムに従って計算した値を出力します。既定プログラムとして、ユーザー定義定数に従って各タリー値を重み付けして加算するモードと、確率論的マイクロドジメトリ(SMK)モデル [10] に従って BNCT における光子等効果線量を計算するモードが組み込まれています。その具体的な使用方法は、 /phits/utility/usranatal をご参照ください。また、PHITS の再コンパイルが必要となりますが、同フォルダには、粒子線治療における生物学的線量を SMK モデルに従って計算するサンプルプログラムも含まれていますので、そちらもご活用下さい。
6.9.2. 分散分析機能¶
スクリプトを利用して、計算条件を変えながら実行した輸送計算の結果を分析することができます。例えば、物質の密度に誤差が含まれる場合、その誤差の範囲で密度を変化させながら輸送計算を実行することで、密度の誤差が計算結果に与える影響を調べることが可能です。PHITS では、専用の分析機能スクリプト autorun.bat (Windows)や autorun.sh (Mac, Linux)を利用することで、計算条件の変化がタリー結果に与える影響を自動的に分析することができます。
ただし、現在のバージョンでは次の制限があります。
利用可能なのは [t-track] と [t-deposit] ( output=dose )のみです。
変えられる計算条件は1つだけです。
anatally サブセクションを指定しますが、 6.10 章 にある itall=3 の場合に指定できる ix 、 iy 、 iz 、 ipart 等のパラメータは利用できません。
分散分析機能は以下のような流れで利用します。
PHITS の輸送計算の入力情報をまとめたインプットファイル(ここでは
phits.inpとする)を用意する。分析機能スクリプト用のインプットファイル(ここでは
autorun.inpとする)を用意する。autorun.inpを入力ファイルとして/phits/binフォルダにあるスクリプトautorun.batまたはautorun.shを実行する。
各インプットファイルの内容とスクリプトの動作の詳細は次節以降でご説明します。
6.9.2.1. 輸送計算のインプットファイル(phits.inp)¶
輸送計算の情報をまとめた phits.inp (ファイル名変更可能)では、変化させたい数値をユーザー定義定数 ci ( \(i=1,\cdots,999\) )により指定してください。また、 [parameters] セクションにおいて icntl=16 としてください。そして、分析機能を利用したいタリーセクションに、次のような anatally サブセクションを設定してください。
1: anatally start
2: manatally = 1
3: sfile = track_a.out
4: anatally end
Anatally サブセクションは、 anatally start と anatally end で挟んだ領域で設定します。 manatally は分析内容を決めるオプションです。 manatally=1 の場合、計算条件 ci の変化がタリー結果に与える影響を分散分析(ANOVA; analysis of variance)に基づき系統的不確かさとして評価します。 sfile は分析結果を出力するファイル名です。
6.9.2.2. 分析機能スクリプト用インプットファイル(autorun.inp)¶
専用のスクリプト( autorun.bat 、 autorun.sh )を実行する際に使用するインプットファイル autorun.inp (ファイル名変更可能)は次の形式で作成してください。
1: file=phits.inp
2: set:c1
3: c-type=2
4: cmin=10
5: cmax=100
6: nc=10
file= の後に、輸送計算の情報をまとめた PHITS のインプットファイル名を書いてください。 set: の後にはそのインプットファイル内で変化させたい計算条件 ci ( \(i=1,\cdots,99\) )の情報を記載してください。 set:c1 の次の行から、 e-type 等のタリーのメッシュタイプと同じ形式で ci のデータを指定します。 c-type=1,2,3 が指定できます。上の例では、 c1= 10 より 100 までを 10 きざみで変化させ、各条件の輸送計算を実行します。
6.9.2.3. スクリプトの動作¶
スクリプト autorun.bat 、 autorun.sh は次の流れで各計算を実行します。
autorun.inpから ci に関する情報を読み取り、nc_info.inpに書き出す。icntl=16 の条件で PHITS を実行し、
phits.inpとnc_info.inpの内容に基づき、輸送計算実行用の一時ファイルphits_tmp.inpと分析用ファイルanatally.inpおよび計算条件ファイルvarfile_j.inp( \(j=1,\cdots,nc\) )を作成する。計算条件を変えて求めた輸送計算の結果をまとめる
outfilesフォルダを作成する。phits_tmp.inpとvarfile_j.inpをインプットファイルとして、合計 nc 回 PHITS を実行する。その際、 \(j\) 番目( \(j=1,\cdots,nc\) )の PHITS のタリー結果は、outfilesフォルダ中に/j/フォルダを作成し、各々移動する。anatally.inpをインプットファイルとして、 icntl=17 の条件で PHITS を実行する。その分析結果を sfile で指定したファイルに書き出す。
6.9.2.4. 出力形式¶
sfile で指定したファイルには、通常のタリー結果の平均値と統計誤差に加え、系統的不確かさ \(u_{\rm syst}\) と全不確かさ \(u_{\rm tot}\) が出力されます。これらは次の関係を満たします。
ここで、 \(N\) は標本数であり、統計誤差は右辺第2項の平方根により計算されます。詳細は文献 [11] を参照してください。
出力は、例えば axis=x 、 part=all の場合は次のようになります。
h: n x y(all ),hh0l n
# x-lower x-upper all r.err
2.0000E-01 4.0000E-01 7.9333E-03 1.3865 1.1539 0.7686
4.0000E-01 6.0000E-01 1.1495E-02 1.3951 1.2479 0.6237
.........
all の列にタリー結果の平均値を出力し、その右側に全不確かさ、系統的不確かさ、統計誤差の順に相対値で出力します。なお、統計量が少ない場合は系統的不確かさの推定値が負となり、その場合は0と出力します。
[t-dchain] の結果に本機能を使用した場合は、 sfile で指定したファイルに全不確かさのみ出力します。通常統計誤差が出力されている箇所に全不確かさが出力されるので、そのファイルを使用して DCHAIN を実行することで、系統的不確かさを含む全誤差の伝播を評価することができます。
6.10. 拡張された統計指標出力機能¶
統計誤差(標準偏差)は、計算によって得られたタリーの平均値の信頼性を判断する重要な統計指標です。しかし、計算を始めたばかりで統計量が少ない時や [weight window] などの統計的な偏りが発生しやすいオプションを使用した場合は、平均値や統計誤差が大きく変化する時があるため、得られた平均値が信頼できるかを確認する指標として統計誤差だけでは不十分な場合があります。そこで、様々な統計指標を出力させてその内容を確認することで、信頼性の高い結果が得られているかどうかを確認するのが本機能の目的です。
タリー結果として通常出力される平均値と統計誤差の全ヒストリー数(バッチ数)の増加に対する各値の推移を出力する他、統計誤差のばらつきの程度を表す分散の分散(VOV: variance of variance)や計算時間に対する統計誤差の減少の度合いを表す性能指数(FOM: figure of merit)の全ヒストリー数に対する推移を出力させます。また、これらの値が統計的に信頼できるかどうかを一覧表で示す statistical check sheet と得られるタリー結果の頻度をまとめた確率密度分布(PDF: probability density function)を出力させることができます。
ただし、現在のバージョンでは、 [t-track] ( mesh=tet を除く)と [t-point] のタリーのみ使用可能です。また、再開始計算には対応していません。(通常出力される平均値と統計誤差は再開始計算によって統計量を加算できますが、VOV、FOM、PDF と各統計量の全ヒストリー数に対する推移の結果は再開始計算時にリセットされます。)
6.10.1. 使用方法¶
本機能を使用する際は、次のパラメータ設定を行ってください。
[parameters] セクションにおいて itall=3 を設定する。
本機能を使用したいタリーセクションにおいて anatally サブセクションを設定する。
本機能を使用したいタリーセクションにおいて iextstat を設定する。 ( anatally サブセクション内のパラメータではないのでご注意ください。)
( iextstat=2 の場合)本機能を使用したいタリーセクションにおいて prodenmn 、 prodenmx 、 nbproden を設定する。 (これらも anatally サブセクション内のパラメータではないのでご注意ください。)
これらの設定を行った上で、 iextstat を 0(初期値)、1、2 と変えることにより、出力させる統計指標の内容を変更することができます。
( iextstat=0 の場合)平均値と統計誤差の全ヒストリー数に対する推移を出力する。
( iextstat=1 の場合)平均値と統計誤差に加えて VOV と FOM の全ヒストリー数に対する推移を出力させ、statistical check sheet を出力する。
C ( iextstat=2 の場合)B) の内容に加えて、PDF を出力する。 この場合は、タリー結果の範囲を確認するテスト計算を実行し、出力範囲を設定して本計算を実行してください。 詳細は 6.10.2.3 章 の C) をご覧ください。
本機能が動作すると、タリーセクションで指定したファイル名の拡張子の前に _StD を付けたファイルを作成し、各バッチ終了時に A)、B)、C) の内容に応じたそれぞれの統計指標をそのファイルに出力します。1つのタリー結果(平均値)あたり、A)、B)、C) のそれぞれの場合に計 2、5、6 ページの eps ファイルが出力されるため、ファイル容量が莫大になる可能性があります。空間メッシュやエネルギーメッシュのビンの数が多い場合は、下に示す anatally サブセクション内のパラメータ設定により、出力させる空間やエネルギーのビンを制限してください。また、A、B、C と出力内容を増やすにしたがって、使用するメモリ容量等の計算機に対する負荷が大きくなるのでご注意ください。
1: anatally start
2: ix = 89 91
3: iz = 61 81 101
4: iy = 1
5: ipart = 1
6: anatally end
Anatallyサブセクションは、 anatally start と anatally end で挟んだ領域で設定します。もし、これらの2行のみでメッシュのビンの指定が無い場合は、全てのビンの結果を出力します。(本統計指標出力機能を使用する場合は、ビンの指定が無い場合でも、2行のみの anatally サブセクションを設定してください。) ix 、 iz 、 iy はそれぞれ x-type 、 z-type 、 y-type で定義した各変数のメッシュのビンを指定するためのパラメータであり、この例の場合、x について 89 と 91 番目のビンを指定しています。指定範囲は各メッシュの全ての組み合わせとなっており、上の例では x について2点と z について3点指定していることから、合計 \(2*3=6\) 個のタリー結果について統計指標を出力させます。 ipart=1 は part= で定義した粒子の内、最初の粒子のみ出力させることを意味しており、例えば part = proton neutron としていた場合、proton に関するタリー結果のみを出力させることになります。
メッシュを指定する変数には、次の10種類があります。 ireg : 領域(セル)、 ix 、 iy 、 iz 、 ir 、 ie 、 it 、 ia : x-type 、 y-type 、 z-type 、 r-type 、 e-type 、 t-type 、 a-type サブセクション、 ipart : part パラメータ、 imul : multiplier パラメータ。省略した変数については、全てのメッシュ点を出力させます。明示的に all を指定することもできます。ただし、 { n1 - n2 } や ( ) の入力方法は使用できません。
なお、 6.9 章 で、複数のタリー結果の解析機能を使用する際にも anatally サブセクションを設定しますが、ここで説明している itall=3 の場合とは使用できるパラメータや考え方が違うのでご注意ください。
1: [parameters]
2: icntl=0
3: maxcas = 1000
4: maxbch = 100
5: itall =3
.........
.........
6: [t-track]
7: mesh = xyz
.........
.........
8: file = track.out
9: epsout = 2
10: iextstat = 2
11: prodenmn = 1E-5
12: prodenmx = 1E-2
13: nbproden = 50
14: anatally start
15: ix = 10
16: iy = 10
17: iz = 50 100
18: ipart = 1
19: anatally end
[parameters] において itall=3 が設定されていることによって、anatally サブセクションが設定されている [t-track] のタリー結果について、拡張された統計指標が出力されます。上の例では、 track_StD.out ファイルが作成され、 track_StD.eps ファイルに図示した結果が出力されます。anatally サブセクションにおいて設定された条件により、x と y について10番目のビン、z について50と100番目のビン、part について1番目の粒子の結果が出力されます。 iextstat=2 となっているため1つのビンの組み合わせに対して6ページ分の出力がありますが、1から6ページに iz=50 に対する結果が出力され、7から12ページに iz=100 に対する結果が出力されます。また、 iextstat=2 の場合に出力されるタリー結果の確率密度分布(PDF: probability density function)について、出力範囲の下限、上限、分割数をそれぞれ prodenmn 、 prodenmx 、 nbproden で設定しており、上の例では \(10^{-5}\) から \(10^{-2}\) の範囲を50分割して PDF を出力します。
6.10.2. 各統計指標の計算方法と出力例¶
前節で示したように、本機能では出力する内容を A)、B)、C) の3つに切り替えることができます。本節ではそれぞれの統計指標の計算方法と出力例や出力結果の分析方法についてまとめます。
6.10.2.1. A) 平均値と統計誤差の全ヒストリー数に対する推移の出力¶
この場合は平均値と統計誤差を出力します。ある \(i\) 番目のヒストリーを計算した際のタリー結果を \(x_i\) とすると、合計 \(N\) 回のヒストリー数によるタリー結果の平均値 \(\bar{x}\) は、
となります。ここで、 \(\sum\) は \(i=1\) から \(N\) までの和を取ることを意味します。なお、ここでは簡単化のためウエイト値は常に1としました。統計誤差として、
により計算されるサンプル平均の標準誤差(standard error of the mean) \(\sigma\) を計算しており、平均値 \(\bar{x}\) との比 \(R=\sigma/\bar{x}\) を統計誤差として出力します。統計的な偏りがない計算であれば、平均値はヒストリー数が増加するにしたがって一定値に収束し、統計誤差は全ヒストリー数 \(N\) に対して \(1/\sqrt{N}\) で減少します。
の場合、出力する eps ファイルの1と2ページ目に、それぞれ平均値(統計誤差を誤差棒で表示)と統計誤差の結果を出力します。横軸を全バッチ数としており、各バッチ終了時にそれまでの全バッチ数に対する結果を示します。 図 6.10.1 に、1 m 厚さのコンクリートの遮蔽体に対して10 MeV 中性子ビームを照射し、照射面と反対側の面における中性子流量をタリーした結果について、本機能を用いて出力した例を示します。 maxcas \(=10^4\) としており、 maxcas の分だけバッチ毎に全ヒストリー数が増加して平均値と統計誤差が推移する状況を確認できます。左パネルの平均値の結果から、40バッチまでは平均値が大きく変化しているものの、それ以降は徐々に一定値に近づいていることがわかります。次に右パネルの結果から、40バッチ以降は統計誤差が減少傾向を示しており、ヒストリー数の平方根の逆数に比例して減少していることが確認できます。
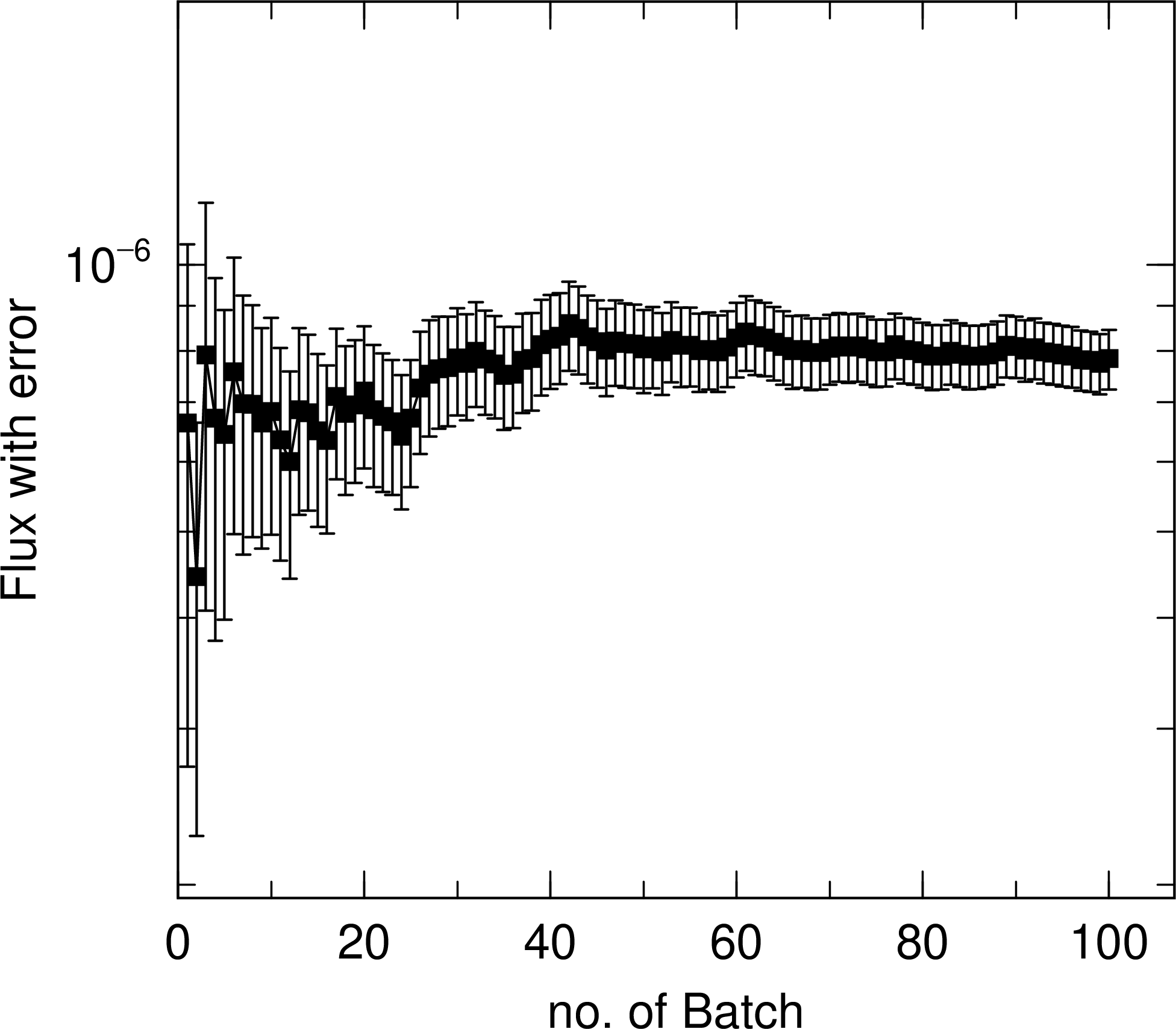
図 6.10.1 平均値の全ヒストリー数(全バッチ数)に対する推移。¶
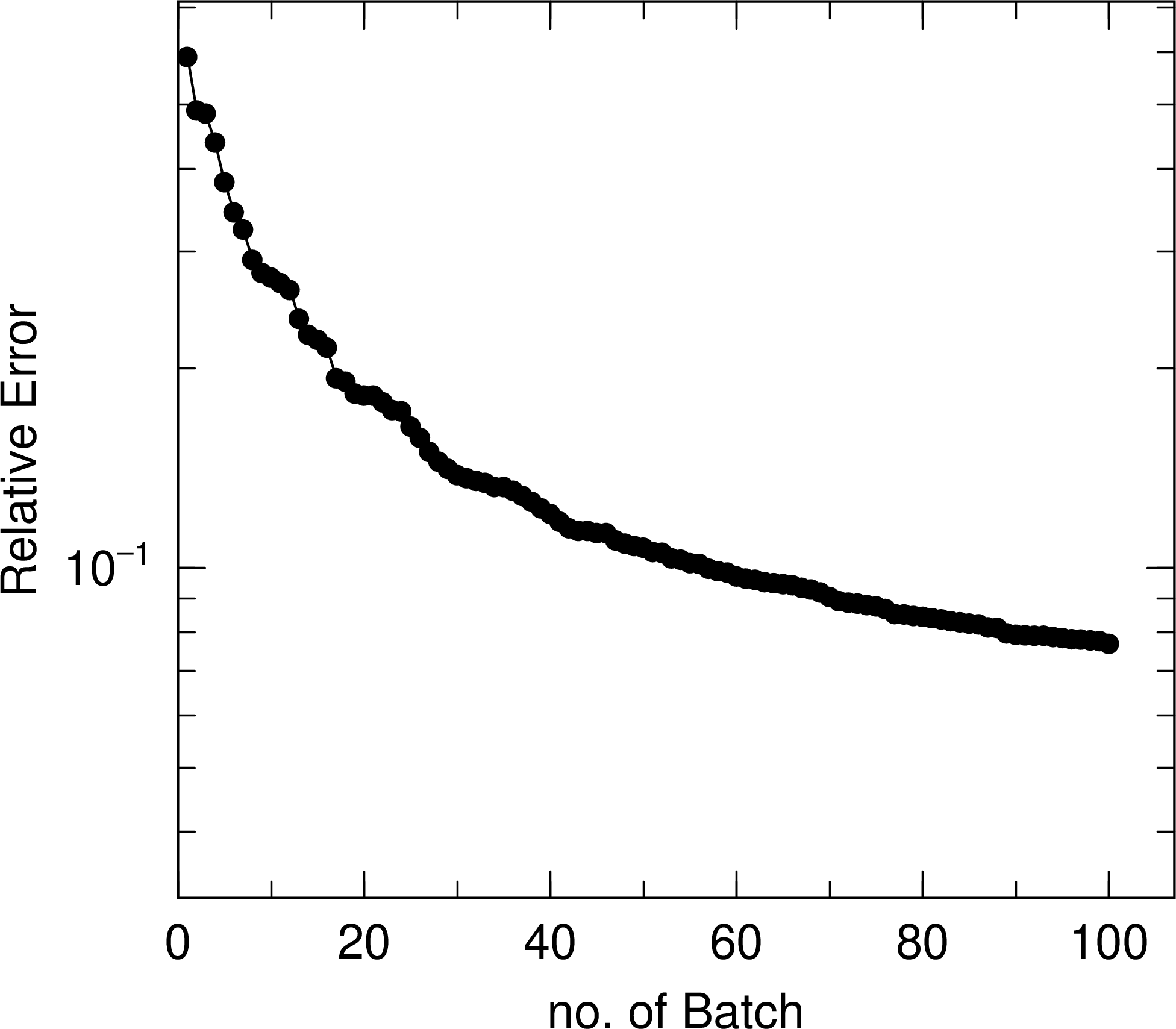
図 6.10.2 統計誤差の全ヒストリー数(全バッチ数)に対する推移。¶
6.10.2.2. B) Statistical check sheet と平均値、統計誤差、分散の分散(VOV: variance of variance)、性能指数(FOM: figure of merit)の全ヒストリー数に対する推移の出力¶
この場合は、A) の内容に VOV と FOM を追加して出力すると共に、これらの統計指標の信頼性をチェックする statistical check sheet を出力します。
VOV は統計誤差のばらつきの程度を表す統計指標であり、各タリー結果 \(x_i\) の平均値 \(\bar{x}\) からのずれ、 \((x_i-\bar{x})\) 、の4乗の和と2乗の和の2乗の比を計算して求めます。
ただし、この式において平均値 \(\bar{x}\) を (6.10.1) により書き換えると、
となるため、具体的にはこの (6.10.3) の表現に基づいて計算しています。 (6.10.2) の右辺第一項を見ると、分子が \(N\) 個の和であり、分母が \(N\) 個の和の2乗であることから、右辺第二項と同様に \(1/N\) の依存性をもつことがわかります。このため、統計量が十分な場合、VOV は \(1/N\) で減少します。
FOM は計算時間に対する統計誤差の減少の度合いを表す統計指標であり、標準誤差 \(\sigma\) と平均値 \(\bar{x}\) の比 \(R\) 及び計算時間 \(T\) [min] を用いて、
により計算します。 \(R\) は \(N\) の平方根に反比例するので、安定した数値計算が行われて \(T\) と試行回数 \(N\) が比例関係を示す場合は、FOM の値は一定となります。逆に、FOM があるヒストリーの前後で大きく変化した場合は、 \(T\) と \(N\) の比例関係がなくなっており、そのヒストリーで非常に長い計算時間が必要であった等の異常を確認することができます。
の場合、1ページ目に statistical check sheet を出力し、2、3、4、5ページ目にそれぞれ平均値、統計誤差、VOV、FOM の全ヒストリー数に対する推移を出力します。 図 6.10.3 に、 図 6.10.1 と同じ計算を行った場合の statistical check sheet を示します。Quantity の列に統計指標の種類、output の列に出力する値の種類を示しています。Value の列に、そのバッチ終了時の値(current value)と全ヒストリー数に対する依存性の評価値(history dep.)を出力しています。Desired の列に各値が統計的に信頼できると判断できる基準値を示しており、pass の列でその基準を満たしているかどうかを判定した結果を示しています。(全ヒストリー数に対する依存性の評価方法や基準を満たす条件については次節で説明します。) 図 6.10.3 の結果では、統計誤差の大きさについての基準( \(<0.05\) )以外は満たしており、安定した計算が実行されていることがわかります。ただ、統計誤差は一番重要な指標なので、その基準を満たす程度には統計量を増やすことが望ましいです。 図 6.10.4 に、VOV と FOM の全ヒストリー数に対する推移を示しています。左パネルから、VOV が40バッチ以降で減少傾向を示しており、 \(1/N\) で減少していることがわかります。一方、右パネルの結果から、FOM が40バッチ以降で一定値に収束している様子を確認できます。
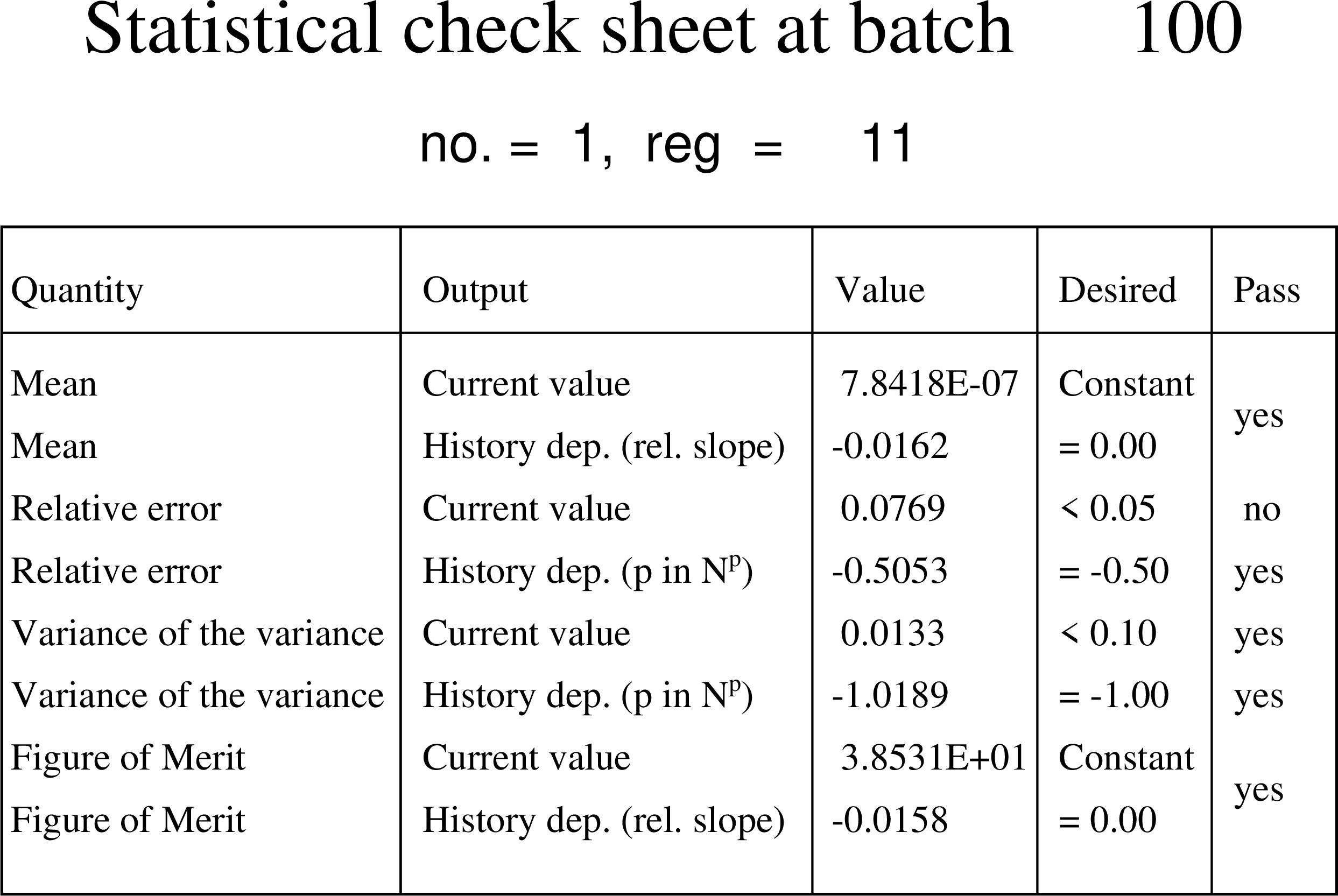
図 6.10.3 100バッチ終了時の statistical check sheet。¶
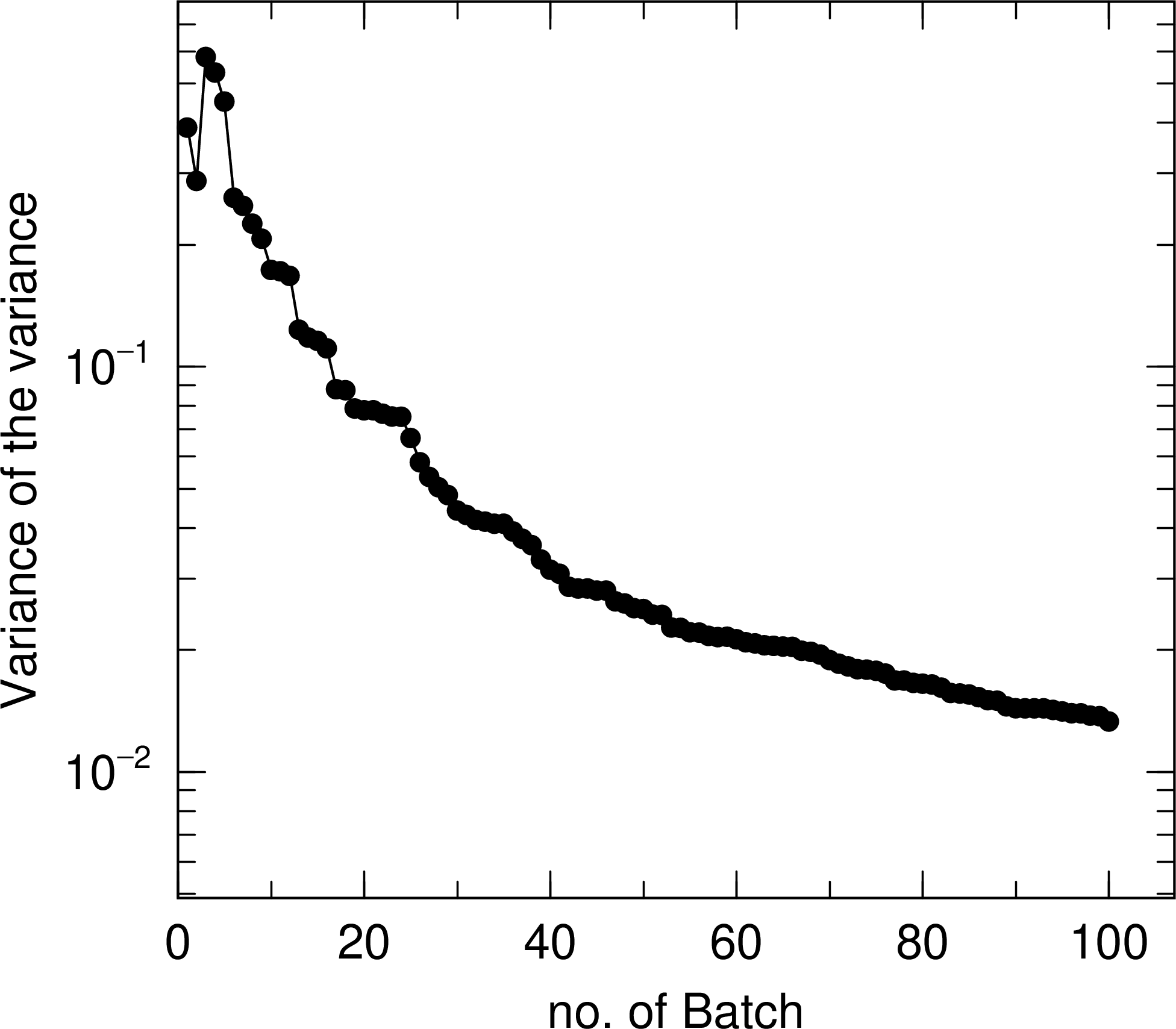
図 6.10.4 分散の分散(VOV)のヒストリー数(バッチ数)に対する推移。¶
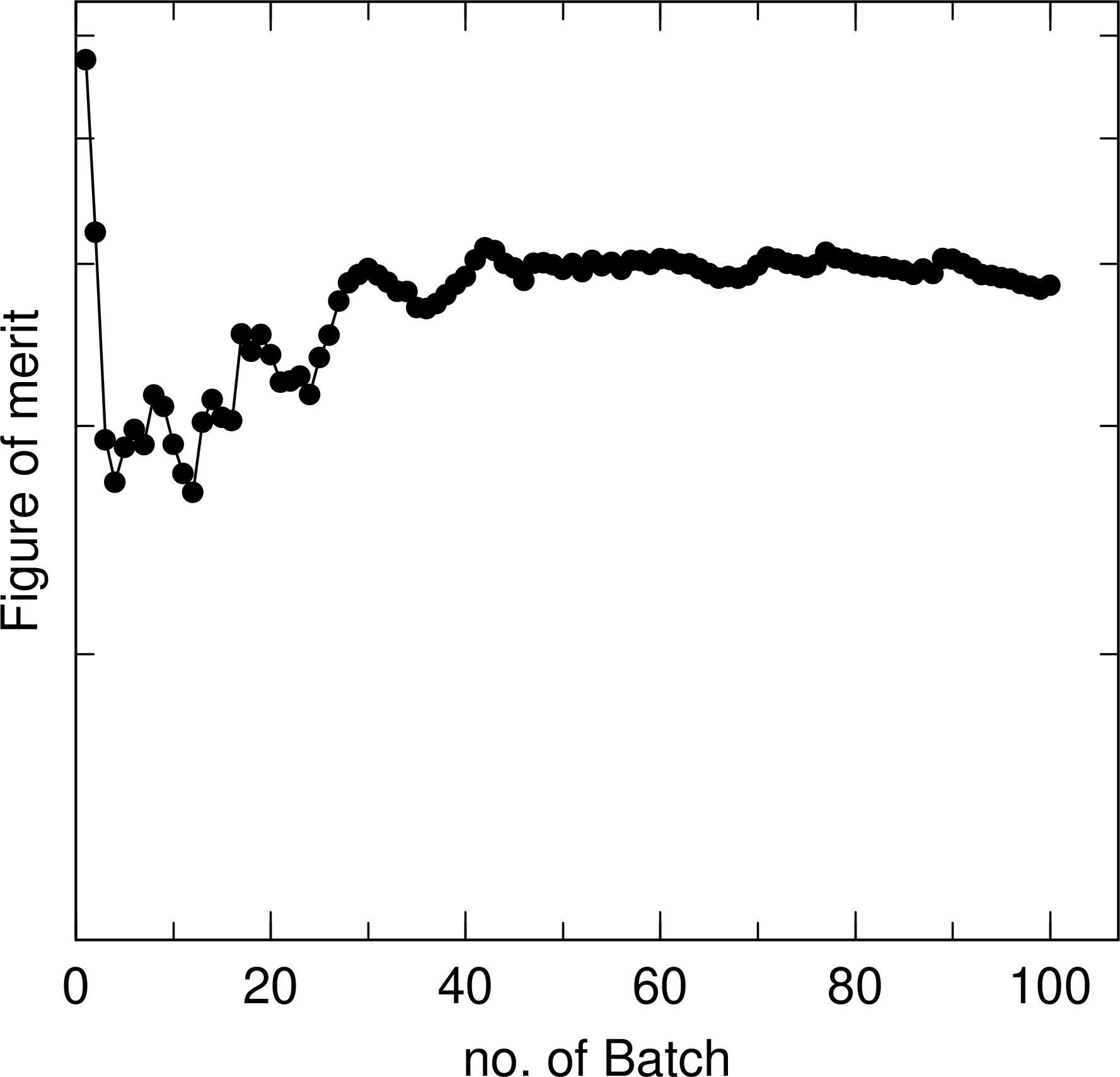
図 6.10.5 性能指数(FOM)のヒストリー数(バッチ数)に対する推移。¶
6.10.2.3. C) Statistical check sheet と平均値、統計誤差、VOV、FOM の全ヒストリー数に対する推移の出力、及びタリー結果の確率密度分布(PDF: probability density function)¶
この場合は、B) の内容に加えて、計算によって得られたタリー結果の頻度分布を表す PDF を出力します。ただし、PDF を出力する範囲を調べるためのテスト計算モードとその範囲を明示的に指定して PDF を求める本計算モードがあるのでご注意ください。基本的に、まずはテスト計算モードで範囲を調べて、その後、出力範囲の下限( prodenmn (D=1e-2))と上限( prodenmx (D=1e+2))及び分割数( nbproden (D=100))を指定して本計算を実施してください。
PDF の計算については、出力するタリー結果の範囲 \([x_{\rm min},x_{\rm max}]\) と対数スケールで分割する数 \(n_{\rm pdf}\) を決めておき、各ヒストリーのタリー結果 \(x_i\) が得られた時に、どのビン番号に入るかを調べ、そのビンのカウント数を増やしていきます。そして、最終的にその分布が積分して1となるように規格化したものを出力します。ここで、タリー結果が0の場合はカウントしないので、分布のピーク位置と平均値 \(\bar{x}\) がずれる場合があります。
テスト計算モードは、PDF の出力に関するパラメータ prodenmn 、 prodenmx 、 nbproden が一つも指定されていない時に動作します。テスト計算モードでは、初期値として \(x_{\rm min}=10^{-2}\) 、 \(x_{\rm max}=10^2\) 、 \(n_{\rm pdf}=100\) として計算を始め、範囲 \([x_{\rm min},x_{\rm max}]\) から外れたタリー結果が得られた場合、その大小関係によって範囲の上限や下限を変更することで、そのタリーが取り得る範囲を自動的に調べます。例えば、 \(10^3\) のタリー結果が得られた場合は、それを10倍した値を上限値とし、 \(x_{\rm max}=10^4\) と変更します。一方、小さいタリー結果が得られた場合は、その値の1/10を \(x_{\rm min}\) とします。このようにして、最終的に出力された PDF の分布を見ることで、そのタリー結果が取り得る範囲が確認できます。ただし、タリー結果が初期値 \(x_{\rm min}=10^{-2}, x_{\rm max}=10^2\) から数10桁も違う値を取る場合は、出力される PDF の横軸の範囲がその桁数だけ広がってしまうのでご注意ください。その場合は、次に示す本計算モードで出力範囲を指定しながら、手動で調整してください。なお、テスト計算モードでは、調整によって範囲が変わる度に記憶した PDF のデータをリセットするため、他の統計指標と違うヒストリー数に対する結果が出力されます。また、MPI や OpenMP による並列計算は使用できません。
次に、 prodenmn 、 prodenmx 、 nbproden のどれか一つでも指定されていると本計算モードが動作します。明示的に指定していないパラメータはそれぞれのデフォルト値が設定されます。本計算モードでは、記憶するタリー結果の範囲が途中で変わることはなく、タリー結果 \(x_i\) の PDF を出力します。ただし、設定された範囲の上限より大きな値がタリー結果として得られた場合は、ワーニングメッセージを出力します。5回程度(並列計算を使用しない場合)でメッセージ出力を止めますが、このメッセージが出たら、一旦計算を止め、上限( prodenmx )を増やしてから再度本計算モードを実行してください。なお、本計算モードでは MPI や OpenMP による並列計算が使用可能です。
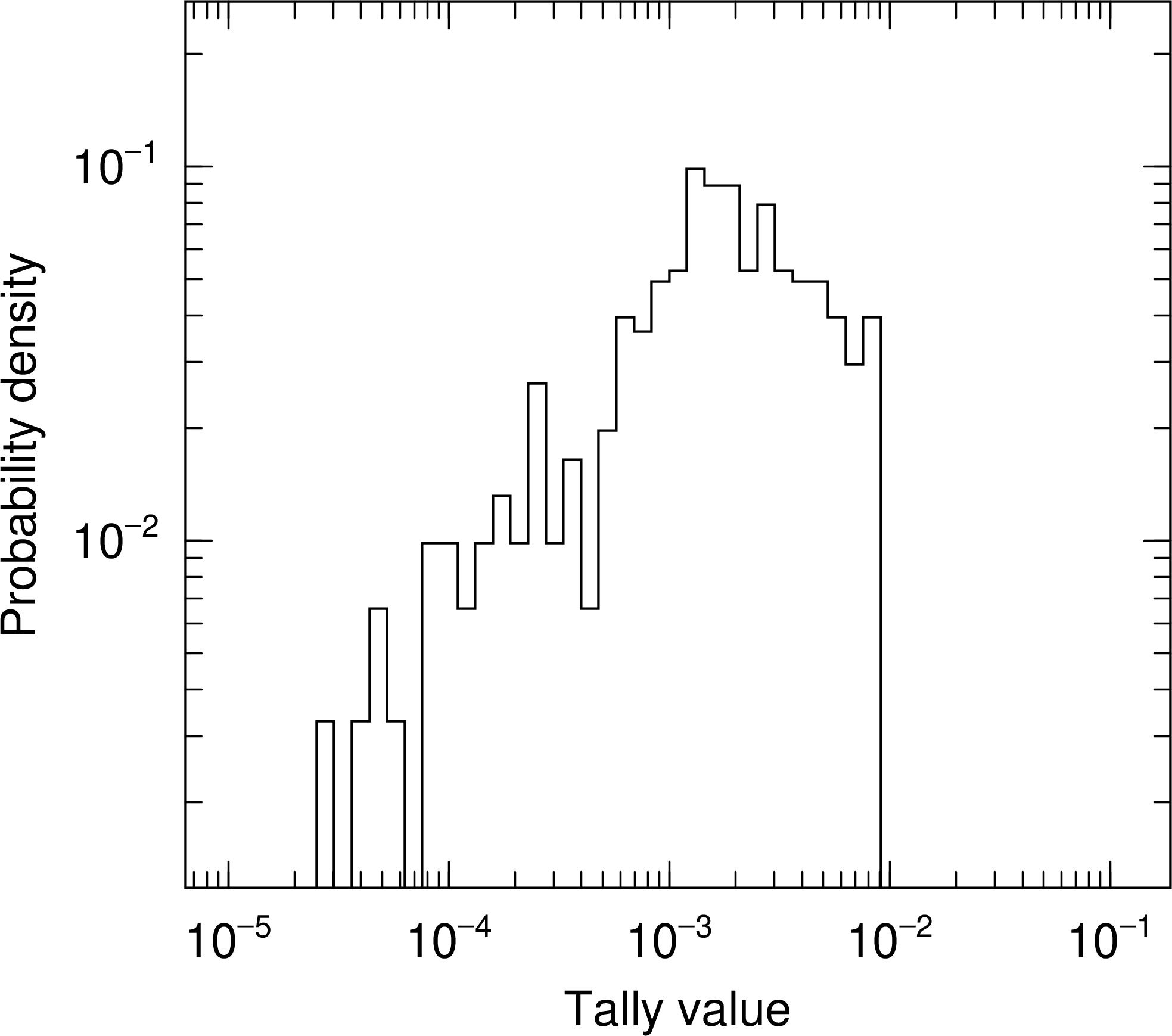
図 6.10.6 タリー結果の確率密度分布(PDF)。¶
の場合、1から5ページ目までは B) の内容と同じです。更に6ページ目にそのバッチ終了時の PDF を出力します。 図 6.10.6 に、 図 6.10.1 と同じ計算を行った場合の PDF を示します。正規分布と判断できる程十分な統計量ではありませんが、 \(10^{-3}\) 辺りにピークをもつ分布であり、およそ \(10^{-4}\) から \(10^{-2}\) の範囲内の値をタリー結果として得ていることがわかります。また、 図 6.10.3 からこのタリー結果の平均値は約 \(10^{-6}\) であり、ピークのある \(10^{-3}\) とは3桁程違っていることから、0で無いタリー結果を得られる割合が1/1000程度であることがわかります。
PDF はタリー結果の具体的な数値を直接的に確認することが可能な指標であり、例えば、分布から(特に大きな値の方に)外れた領域に値を持っているといった異常を発見しやすくなります。ただし、きれいな分布構造を確認するためには、他の統計指標と比べて多くのヒストリー数が必要となるのでご注意ください。この観点から、PDF は statistical check sheet の項目には入れておりません。
6.10.3. Statistical check sheet¶
この check sheet では、平均値、統計誤差、分散の分散(VOV: variance of variance)、性能指数(FOM: figure of merit)に関するバッチ終了時の値(current value)と全ヒストリー数に対する依存性(history dep.)を出力し、統計的に信頼できる基準値と比較することで、合計6個のチェック項目について pass したかどうかを判定します。
ヒストリー数に対する依存性は全ヒストリーの後半の結果から評価しており、例えば100バッチが終了した時は51から100バッチの時の値を使って評価します。平均値と FOM はヒストリー数依存性がない、すなわち一定値に収束することから、 \(f(N_{\rm batch})=aN_{\rm batch}+b\) の関数(ここで、 \(N_{\rm batch}\) は全バッチ数)を仮定して最小二乗法でフィッティングを行い、その係数 \(a\) が0に近いかどうかで判定します。具体的には、この係数を最終バッチ時の値で規格化した値の絶対値が0.05未満であれば yes とし、以上であれば no と判定します。統計誤差については、ヒストリー数の平方根の逆数に比例することから、 \(f(N_{\rm batch})=b\exp(aN_{\rm batch})\) の関数を仮定して最小二乗法でフィッティングを行い、係数 \(a\) が \(-0.5\) に近いかどうかで判定します。具体的には、 \(-0.475\) から \(-0.525\) の範囲にあれば yes とします。VOV については、ヒストリー数に対して反比例となることから、統計誤差と同様の関数系を仮定して最小二乗法を行い、係数 \(a\) が \(-1.0\) に近いかどうかで判定します。具体的には、 \(-0.95\) から \(-1.05\) の範囲にあれば yes とします。
この check sheet で pass の判定に用いている基準値は絶対的なものではないことにご注意ください。計算条件や目的とする計算精度によって、計算結果の信頼性を判断する基準は変わります。6個の全てが yes だからといって、常にその結果が信頼できるわけではありません。逆に、ある項目が no となっていても、その統計指標のヒストリー数に対する推移を確認することで、問題ないと判断できる場合もあります。